


How to build Git from scratch
Initialize a Repo and Hashing Objects

I never fully understood how Git works as a software engineer or why it’s such a big deal, so I figured I might as well try to learn how it works under the hood from scratch. That’s why I decided to build Tit, a Git client in Python.
Initialize a Repo
When we run git init, several files and folders are created:

config – Contains repo-specific config settings and can override user-level Git config for a repo.
description – Displays the repo description; apparently, it’s rarely used.
HEAD – References the current branch or commit. When created, it points to
refs/heads/mainor a direct commit hash (in a detached HEAD state).hooks – Contains 13 scripts that are triggered before and after commits.
info – Contains metadata and an
excludefile, which defines ignored patterns not tracked by Git (similar to.gitignore).objects – Stores all the fundamental units of data storage within the repo:
blob – File content.
trees – Directory structures.
commits – Snapshots of the project at a point in time.
tags – References to specific commits, used for version marking.
Let’s attempt the same with a .tit directory.
def write_file(path, content):
"""
Write content to a file at the specified path.
Creates the file if it doesn't exist, or overwrites it if it does.
Args:
path (str): Path where the file should be written
content (bytes): Content to write to the file
Returns:
None
"""
with open(path, 'wb') as f:
f.write(content)
def init(repo):
"""
Create a directory for the repository and initialize a .tit directory structure.
This function mimics Git's init command by creating the basic directory
structure needed for version control:
1. Creates the repository directory if it doesn't exist
2. Creates a .tit directory for metadata
3. Sets up objects and refs directories
4. Creates a HEAD file pointing to the master branch
Args:
repo (str): Name of the repository to initialize
Returns:
None: Prints a success message upon completion
"""
if not os.path.exists(repo):
os.mkdir(repo)
tit_dir = os.path.join(repo, ".tit")
if not os.path.exists(tit_dir):
os.mkdir(tit_dir)
for name in ['objects', 'refs', 'refs/head']: # Basic directory structure for version control
path = os.path.join(tit_dir, name)
if not os.path.exists(path):
os.mkdir(path)
# Create HEAD file pointing to the master branch
write_file(os.path.join(tit_dir, 'HEAD'), b'ref: refs/heads/master')
print(f'Initialized empty tit repository: {repo}. Don\'t be a tit, commit early and often.')Hashing Objects
Inside .git/objects, there are two folders:
info: Primarily used for Git's internal operations, particularly in distributed environments.
pack: Stores compressed collections of Git objects as
.packfiles (like "packing" them together).

Let's say I create a new file in the working directory and explicitly tell Git to track it by running git add. After doing this, we notice that Git creates a new folder.
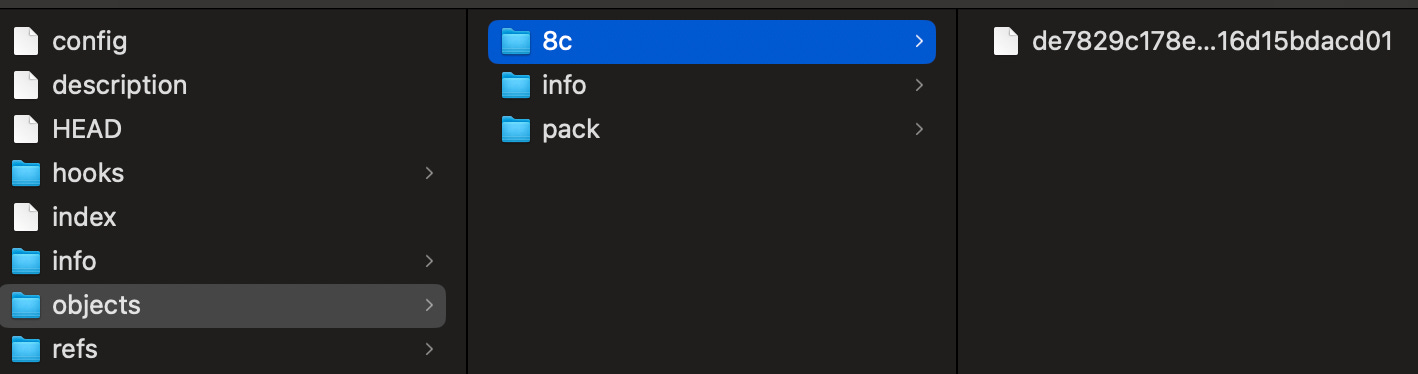
Here's what Git is doing:
Preparing the object: Git prepends a header containing the object type and content size in bytes. This header is followed by a NUL byte and then the file's actual data bytes.
Calculating SHA-1 hash: Git calculates the SHA-1 hash of the file's content, giving each file's content a unique identifier. This hash enables Git to reference the exact content and also serves as a checksum. If the content changes even slightly, the resulting hash will be completely different, allowing Git to detect any corruption or tampering. Another benefit is deduplication—if multiple files have identical content (and thus identical hashes), Git stores the content only once, greatly aiding storage efficiency, especially in large repositories.
Compressing and storing: Git compresses the data using zlib compression and stores it in
.git/objects/ab/cd..., whereabrepresents the first two characters of the 40-character SHA-1 hash andcdrepresents the remaining 38 characters. Although a different compression algorithm could be used, zlib was already mature when Git was released, which is why it remains in use.
Here’s the code that mimics Git's internal hashing mechanism.
def hash_object(data, obj_type, write=True):
"""
Compute hash of object data of given type and write to object store if requested.
This function mimics Git's internal object hashing mechanism:
1. Prepends a header with the object type and content size
2. Calculates a SHA-1 hash of the resulting data
3. Optionally writes the zlib-compressed content to the object store
Args:
data (bytes): Raw data to hash
obj_type (str): Object type ('blob', 'commit', 'tree', or 'tag')
write (bool, optional): If True, write object to object store. Defaults to True.
Returns:
str: SHA-1 object hash as a hexadecimal string
"""
# Create the header in the format "type size" (e.g., "blob 16")
header = f"{obj_type}{len(data)}".encode()
# Concatenate header, null byte separator, and data to form the full content
# The null byte (\x00) separates the header from the actual content
full_data = header + b'\x00' + data
# Calculate SHA-1 hash of the full content
# This hash will be used as the object's identifier in the object store
sha1 = hashlib.sha1(full_data).hexdigest()
if write:
# Determine the path where the object will be stored
# First 2 characters of hash become directory name, rest become filename
# This distributes objects across directories to avoid having too many files in one directory
path = os.path.join('.tit', 'objects', sha1[:2], sha1[2:])
# Only write the object if it doesn't already exist
if not os.path.exists(path):
# Create the directory structure if it doesn't exist
os.makedirs(os.path.dirname(path), exist_ok=True)
# Write the zlib-compressed content to the object store
# Git uses zlib compression to reduce storage space
write_file(path, zlib.compress(full_data))
# Return the full hash as a hexadecimal string
return sha1